文章目錄
robots.txt 是放在網站根目錄中的純文字檔,用來告訴搜尋引擎爬蟲哪些網站路徑允許爬取、哪些路徑不允許或不建議爬取。對 SEO 來說,它不是提升排名的開關,也不是保護機密資料的方法,而是一個用來管理搜尋引擎爬蟲存取網站內容的規則檔案。
簡單來說,robots.txt 就像是給搜尋引擎爬蟲看的「網站通行規則」。當 Googlebot 造訪網站時,通常會先查看 robots.txt,了解哪些路徑可以進入,哪些路徑不應該抓取。
1. robots.txt 是什麼?先分清楚爬取與索引
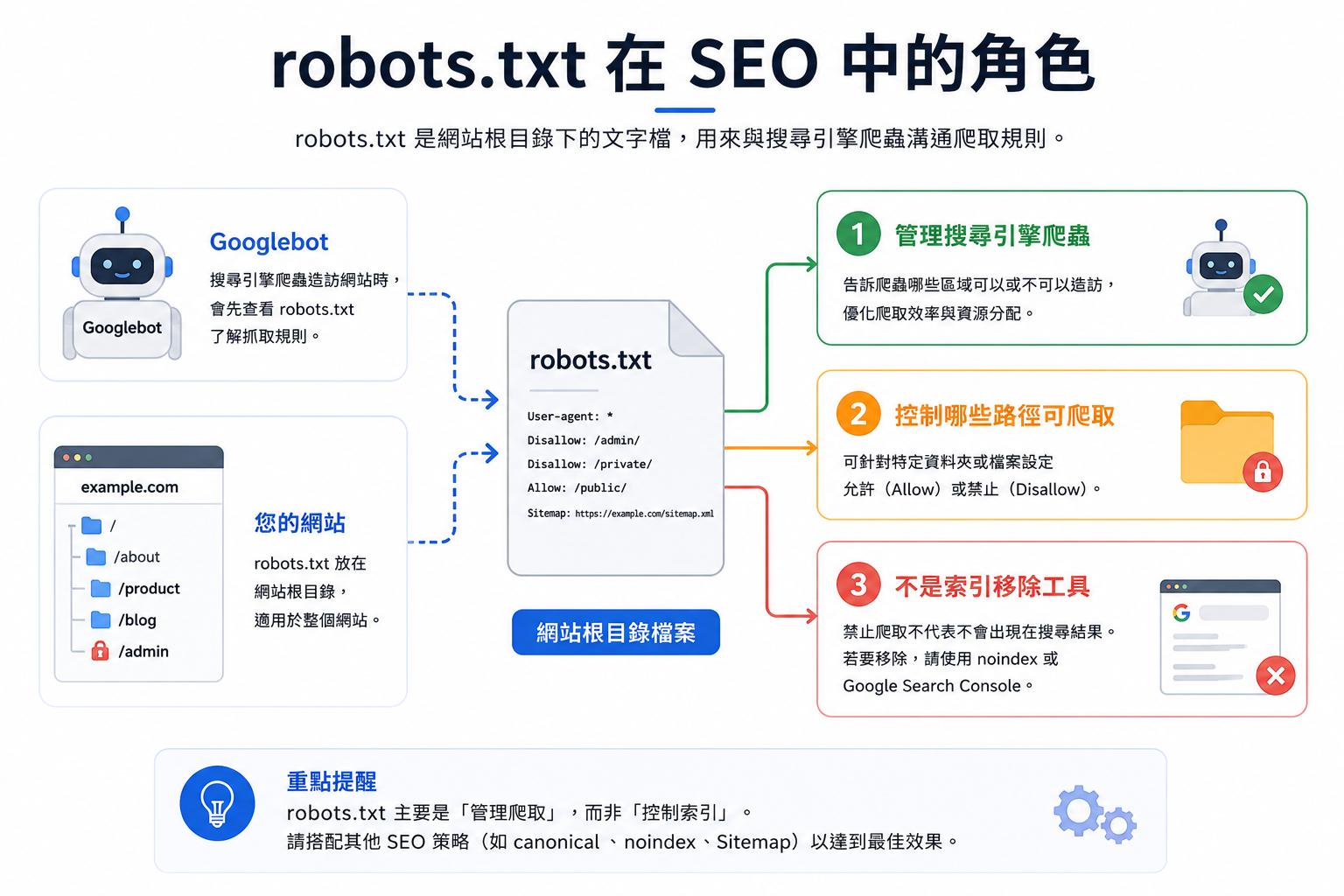
robots.txt 通常放在網站根目錄,常見網址如下:
https://www.example.com/robots.txt
它的主要用途是告訴搜尋引擎爬蟲:「這些路徑可以抓取,這些路徑不要抓取。」
例如:
User-agent: *
Disallow: /admin/
Disallow: /cart/
Sitemap: https://www.example.com/sitemap.xml
這段設定的意思是:
| 設定項目 | 意思 |
| User-agent: * | 適用於多數搜尋引擎爬蟲 |
| Disallow: /admin/ | 不希望爬蟲抓取後台路徑 |
| Disallow: /cart/ | 不希望爬蟲抓取購物車頁面 |
| Sitemap | 告訴搜尋引擎 Sitemap 位置 |
對 SEO 來說,robots.txt 常用來避免搜尋引擎浪費爬取資源在不重要的頁面,例如後台、購物車、會員中心、站內搜尋結果、篩選參數頁等。
但 robots.txt 不適合用來隱藏機密資料。因為 robots.txt 是公開檔案,任何人只要輸入網址就可能查看內容。如果有真正不想被外界看到的資料,應該使用登入權限、密碼保護或伺服器端權限控管,而不是只靠 robots.txt。
另外,不同子網域通常需要各自檢查 robots.txt。例如:
https://www.example.com/robots.txt
https://blog.example.com/robots.txt
https://shop.example.com/robots.txt
如果網站同時有官網、部落格與商店子網域,不能只檢查主網域的 robots.txt。
這裡有一個非常重要的觀念:robots.txt 主要管理的是「爬取」,不是直接管理「索引」。如果你的目標是不要讓某個頁面出現在 Google 搜尋結果中,通常應該使用 noindex、X-robots-Tag、密碼保護或移除頁面,而不是只依賴 robots.txt。
2. robots.txt 怎麼設定?基本語法與常見範例

robots.txt 的基本語法不複雜,常見指令包含 User-agent、Disallow、Allow 與 Sitemap。
| 語法 | 功能說明 | 範例 |
| User-agent | 指定規則適用的爬蟲 | User-agent: Googlebot |
| Disallow | 禁止爬蟲抓取特定路徑 | Disallow: /admin/ |
| Allow | 允許爬蟲抓取特定路徑。多數情況下,沒有被 Disallow 封鎖的路徑預設可被爬取;Allow 通常用在某個目錄被封鎖時,例外開放其中一部分資源或路徑。 | Allow: /blog/ |
| Sitemap | 提供 Sitemap 位置 | Sitemap: https://www.example.com/sitemap.xml |
常見範例一:一般企業官網
如果是一般企業官網,沒有複雜會員系統或大量參數頁,可以先用簡單版本:
User-agent: *
Disallow: /wp-admin/
Disallow: /search/
Sitemap: https://www.example.com/sitemap.xml
這類設定適合多數 WordPress 企業網站,能避免爬蟲進入後台與站內搜尋結果頁,同時保留重要頁面被正常爬取。
常見範例二:WordPress 網站
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://www.example.com/sitemap.xml
這類設定常見於 WordPress 網站。它可以避免爬蟲抓取後台管理路徑,同時保留部分前台功能需要使用的資源。
常見範例三:禁止抓取站內搜尋結果頁
User-agent: *
Disallow: /search/
Disallow: /*?s=
站內搜尋結果頁通常內容重複性高,對 SEO 價值有限,也可能造成大量低品質 URL 被爬取,因此不少網站會選擇阻擋。
常見範例四:電商網站參數頁
User-agent: *
Disallow: /cart/
Disallow: /checkout/
Disallow: /member/
Disallow: /*?sort=
Disallow: /*?filter=
Sitemap: https://www.example.com/sitemap.xml
這類設定常見於電商網站。如果商品篩選、排序、價格條件會產生大量相似網址,就可能需要規劃 robots.txt、canonical、noindex 或參數控管策略。
不過要提醒:不要看到參數頁就全部封鎖。某些分類或篩選頁如果有明確搜尋需求,也可能具備 SEO 價值,應先判斷該頁面是否值得被檢索與收錄。
3. robots.txt、noindex、canonical 差在哪?新手最容易搞混的地方
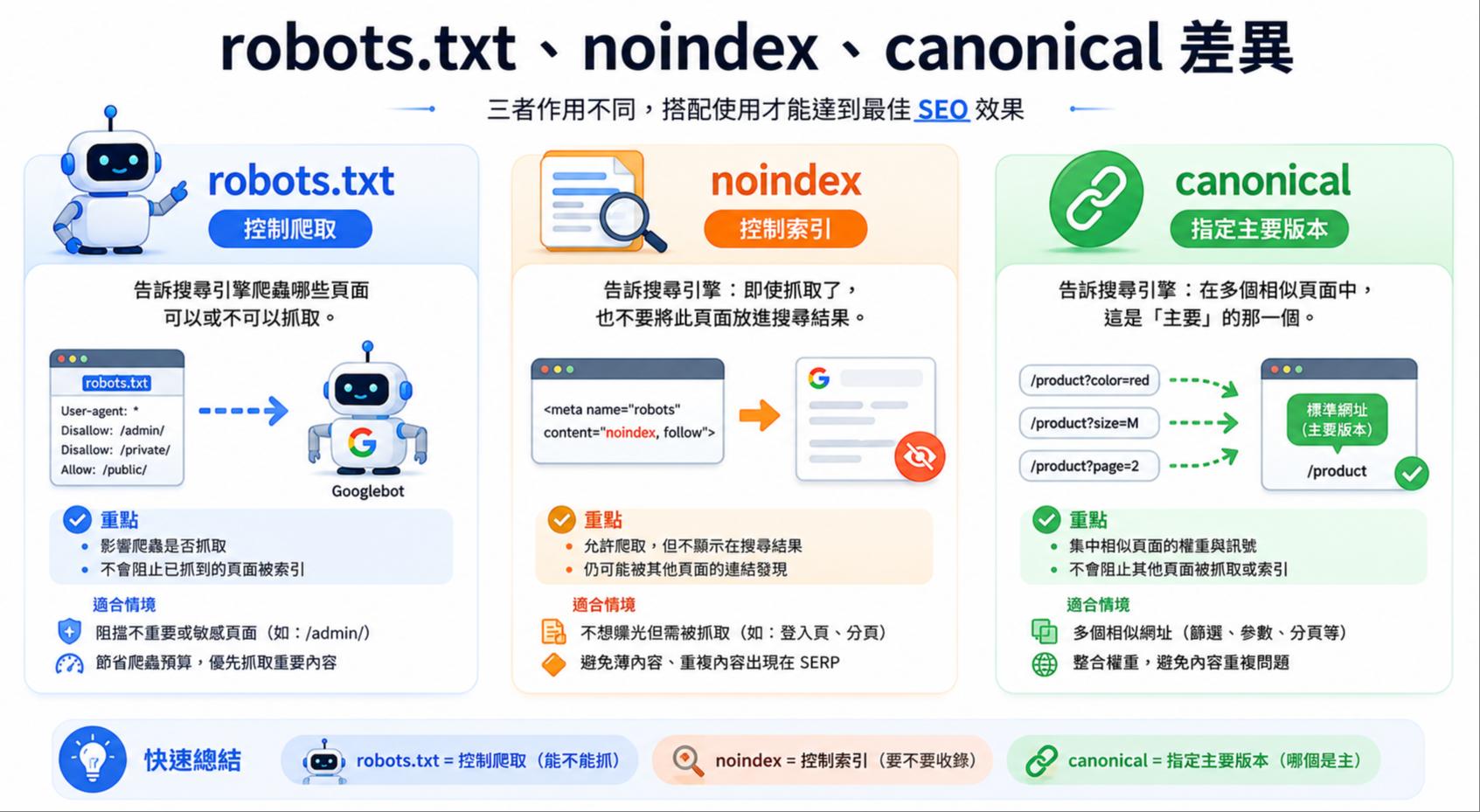
很多 SEO 新手會把 robots.txt、noindex、canonical 混在一起,但它們的用途其實不同。
| 工具 | 主要功能 | 適合情境 | 常見誤用 |
| robots.txt | 管理爬蟲是否可以爬取某些路徑 | 不希望爬蟲浪費資源抓取後台、搜尋結果、參數頁 | 拿來阻止頁面被索引 |
| noindex | 告訴搜尋引擎不要將頁面放入索引 | 不希望頁面出現在搜尋結果 | 同時用 robots.txt 擋住,導致爬蟲看不到 noindex |
| canonical | 告訴搜尋引擎哪個網址是主要版本 | 多個相似頁面需要集中主要版本訊號 | 把 canonical 當成強制移除工具 |
最重要的差異是:
- robots.txt 是「不要抓」。
- Noindex 是「不要收錄」。
- Canonical 是「主要版本看這個」。
舉例來說:
- 如果你不希望 Google 抓取後台頁面,可以用 robots.txt。
- 如果你不希望某個活動頁出現在搜尋結果,但仍允許 Google 讀取頁面,就應該用 noindex。
- 如果同一篇文章有多個網址版本,例如帶有 UTM 參數、分類路徑或列印版頁面,就應該考慮 canonical。
這三者不是誰比較好,而是用途不同。實務上經常會一起搭配使用,但不能互相亂替代。尤其要注意,如果頁面已經被 robots.txt 阻擋,搜尋引擎可能無法讀到頁面上的 noindex,反而讓索引排查變得更麻煩。
4. robots.txt 設定常見錯誤:這些問題很容易傷到 SEO
robots.txt 看起來只是簡單文字檔,但如果設定錯誤,可能會讓重要頁面無法被 Google 正常爬取。
錯誤一:把整個網站都封鎖
User-agent: *
Disallow: /
這段設定代表禁止所有爬蟲抓取整個網站。如果這是正式站的 robots.txt,可能會讓 Google 無法正常爬取網站內容。
這種錯誤常發生在網站改版或測試站搬到正式站時,工程團隊忘記移除測試環境的封鎖規則。新站上線、改版、換主機後,這是最需要優先檢查的項目。
錯誤二:用 robots.txt 當作 noindex
有些人以為只要在 robots.txt 擋住某個頁面,該頁就不會出現在搜尋結果。這個觀念不精準。
robots.txt 可以阻止爬蟲抓取,但不一定能完全阻止網址被索引。如果其他網站連到該網址,搜尋引擎仍可能知道這個 URL 的存在。若目標是避免頁面長期出現在搜尋結果,應使用 noindex、密碼保護或移除頁面;Search Console 移除工具較適合短期、暫時性的搜尋結果移除需求。
錯誤三:封鎖 CSS、JS 或重要圖片資源
如果網站把重要的 CSS、JavaScript 或圖片資源封鎖,搜尋引擎可能無法正確理解頁面呈現方式。尤其是現代網站常依賴 JavaScript 載入內容,如果關鍵資源被擋住,搜尋引擎看到的頁面可能和使用者看到的不一樣。
錯誤四:封鎖了重要內容路徑
例如:
User-agent: *
Disallow: /blog/
如果 /blog/ 是網站主要內容區,這樣會讓搜尋引擎無法抓取所有部落格文章。對內容型網站來說,這會是很嚴重的 SEO 問題。
錯誤五:把私密路徑寫進 robots.txt
robots.txt 是公開檔案,不是資安保護工具。如果把機密後台、測試環境或敏感檔案路徑寫在 robots.txt 中,反而可能讓有心人士知道網站有哪些目錄。
如果資料真的不能被看到,應該使用登入驗證、密碼保護、伺服器權限控管或移除公開連結。
5. robots.txt 設定與檢查流程:新手可以照這樣做

如果你是第一次處理 robots.txt,可以用以下流程降低出錯機率。
第一步:先確認哪些頁面需要被搜尋引擎看到
請先盤點網站重要頁面,例如:
- 品牌首頁
- 服務頁
- 產品頁
- 分類頁
- 部落格文章
- 案例頁
- 聯絡頁
這些通常是希望 Google 能正常爬取,並有機會被索引的頁面,不應該被 robots.txt 擋住。
第二步:整理不需要被爬蟲抓取的路徑
常見可能不需要抓取的頁面包含:
- 後台管理頁
- 購物車頁
- 會員中心
- 站內搜尋結果
- 低價值參數頁
- 測試頁
- 重複性高的系統頁
但是否要封鎖,仍要看網站架構與 SEO 策略,不能一律套用。
第三步:確認 robots.txt 放在正確位置
robots.txt 必須放在網站根目錄,例如:
https://www.example.com/robots.txt
如果網站有不同子網域,例如:
https://blog.example.com
https://shop.example.com
不同子網域可能需要各自的 robots.txt 規劃。
第四步:確認 Sitemap 是否正確標示
robots.txt 中可以加入 Sitemap 位置,例如:
Sitemap: https://www.example.com/sitemap.xml
這能幫助搜尋引擎更容易找到網站的重要 URL。不過,Sitemap 本身不保證收錄,仍要看頁面品質、可爬取性、可索引性與網站整體訊號。
第五步:上線後用 Google Search Console 檢查
設定完成後,建議至少檢查幾個項目:
- 重要頁面是否可被爬取
- 重要頁面是否被意外封鎖
- Sitemap 是否可正常讀取
- Google Search Console 是否出現「遭 robots.txt 封鎖」相關狀態
- 網站流量與索引狀態是否有異常變化
將能數位行銷在檢查技術 SEO 時,通常不會只看 robots.txt 有沒有存在,而會一起看 Sitemap、noindex、canonical、內部連結與 Search Console 訊號,因為真正影響收錄的往往是多個設定互相作用。
robots.txt 是管理爬蟲的工具,不是索引與資安萬用解法
robots.txt 是 SEO 技術設定中的基礎檔案,主要用途是管理搜尋引擎爬蟲可以爬取哪些路徑。它適合用來節省爬蟲資源、降低低價值頁面被爬取的機率,也能協助大型網站整理爬取優先順序。
但 robots.txt 不是索引移除工具,也不是資安保護工具。設定前,應先確認你的目標是控制爬取、避免索引、整合重複頁,還是保護資料。目的不同,該用的技術也不同。
對台灣企業網站來說,最穩的做法是把 robots.txt 納入定期技術 SEO 檢查,尤其在網站改版、搬站、CMS 更新或新增大量分類頁時重新驗證,避免一個小小的設定錯誤影響自然搜尋表現。
robots.txt 如何運作
robots.txt 文件的作用是告訴搜尋引擎爬蟲哪些頁面它們可以訪問,哪些頁面它們不應該訪問。這有助於確保搜尋引擎爬蟲只索引你希望被索引的內容,從而提高網站的能見度和檢索效率。
PS:需要注意的是,robots.txt 只是一個建議,而不是一個絕對的禁令。
一些不道德的爬蟲可能會忽略這個文件,因此,網站持有者不應該依賴它來保護敏感信息,對於關鍵隱私內容,最好採取其他更加強有力的保護措施,例如密碼保護或其他身份驗證方式。
綜上所述,robots.txt 是個非常有用的工具,正確運用可以優化網站SEO。希望這篇入門指南能幫助大家更理解它的運作方式!如果說對以上內容還有疑問,需要專業人員協助,也都歡迎聯繫我們將能數位行銷呦!
延伸閱讀:
- Google 優化排名怎麼做?2023 提升網站排名SEO 必備思維!
- SEO 關鍵字蠶食 (keyword cannibalization) 是什麼?修復全指南
- SEO 趨勢 2025:內容叢集(Topic Cluster)打造穩固的 SEO 排名

 設為 Google 偏好來源
設為 Google 偏好來源